Data Management in Distributed Systems
Partitioning
Process of dividing a dataset into smaller parts and distributing them across multiple nodes in a distributed system. This improves
- Scalability - Allows handling larger datasets by spreading the load.
- Performance - Enables parallel processing, reducing query response time.
- Fault Tolerance - Prevents system-wide failures by localizing issues.
Types of Partitioning
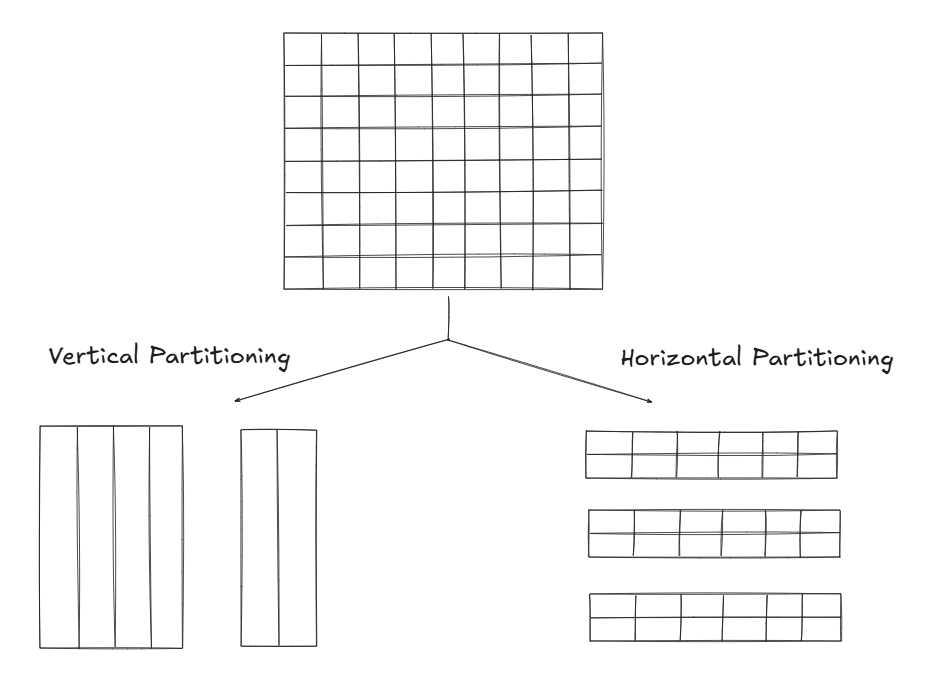
- Vertical Partitioning : Split a table into multiple tables with fewer columns (Normalization is a way to vertically partition, but can go beyond that too)
- Horizontal Partitioning : Split a table into multiple smaller tables with same columns but rows are split.
Note - Sharding is a type of horizontal partitioning where data is distributed across multiple databases.
Horizontal Partitioning Strategies
-
Range Partitioning
Split the dataset into ranges according to value of specific attribute.
Ex: User IDs 1-1000 → Node 1, 1001-2000 → Node 2, etc.
-
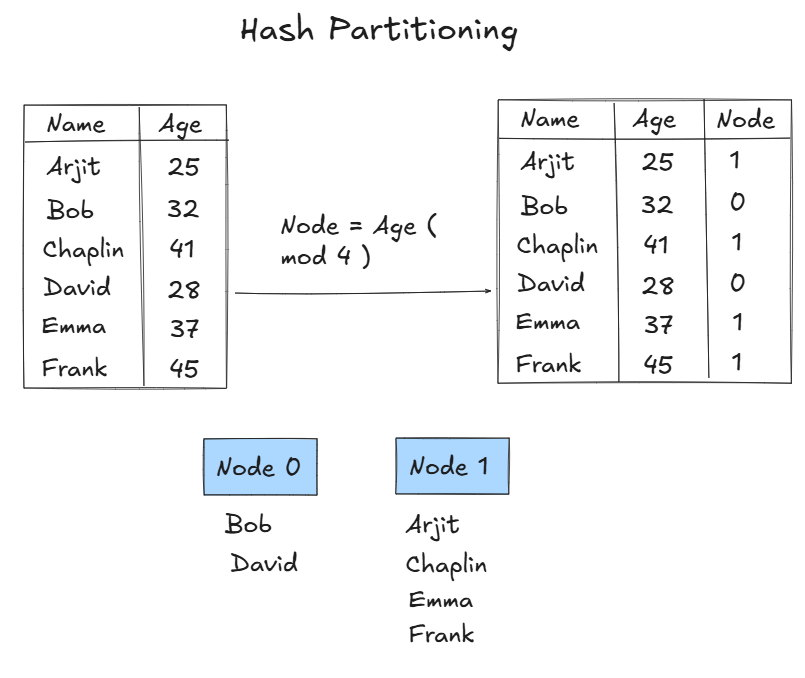
Hash Partitioning
Apply hash function to a attribute of each row and based on that store it in the resultant node. On failure of a node, re-hash takes place which results in significant data movement.
-
Consistent Hashing
Solves the increased data movement problem on re-hashing.
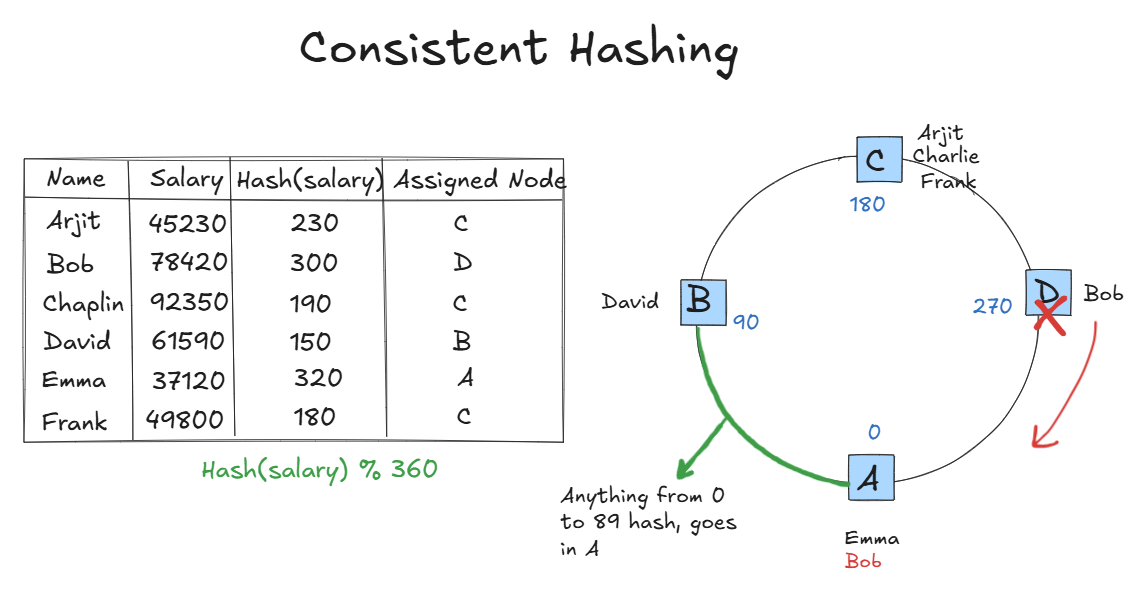
On Failure of Node D, Only data of Node D will move to Node A (clockwise)
Replication
Storing the same piece of data in multiple nodes (called replicas) so even if one crashes other nodes can serve the requests. This helps in improving availability, read performance, and fault tolerance.
Types of Replication
- Pessimistic : Tries to guarantee from beginning that all replicas are identical to each other. Ensures strong consistency.
- Optimistic : Also called lazy replication allows the different replicas to diverge with gurantee that they will converge at a point of time. Ensures high availability.
Primary Backup Replication (Single Master Replication)
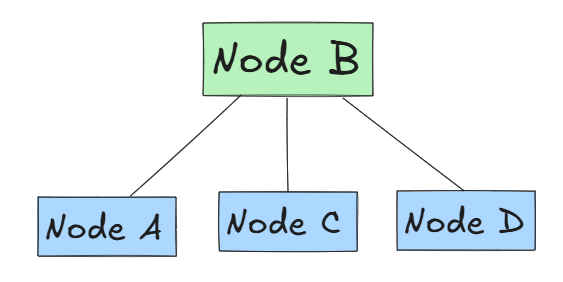
Designate a single node amongst the replicas as the leader, that receives all the updates, while Followers replicate data and serve read requests.
Techniques for Propagating updates -
- Synchronous Replication : Primary node replies to client to indicate that Write is complete only after receiving acknowledgements from replicas.
- Asynchronous Replication : Primary node replies to client as soon as written on Master and then later updates other followers of the update. Can cause Consistency and durability issues but is faster.
Multi Primary Replication (Multi Master Replication)
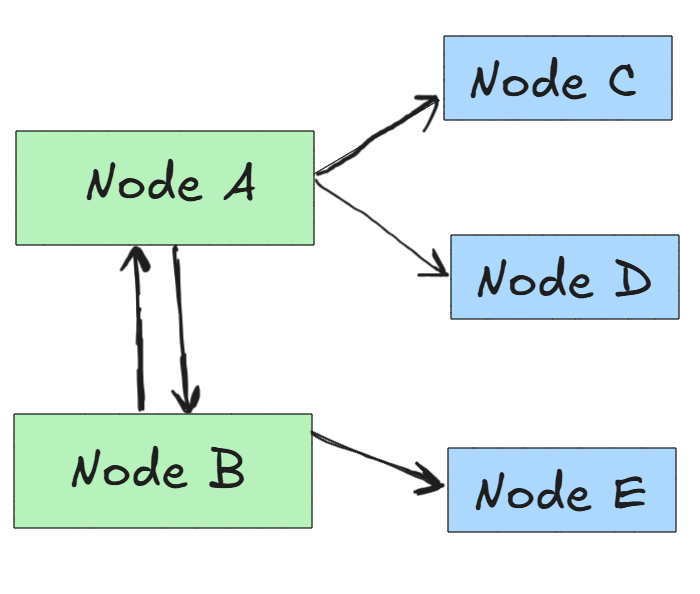
All replicas are equal and can accept write requests, this results in higher availability and performance over consistency.
Conflict Resolution in Multi Primary Replication
There are 2 ways - Eagerly (Conflict is resolved during write operation) or Lazily (Eventual resolution )
Approaches -
- Exposing conflict resolution to clients - Send multiple versions to client and client selects the right version. Ex - Shopping cart
- Last Write wins - Each node in system tags each version with a timestamp, during conflict version with latest timestamp is kept.
Quorums in Distributed Systems
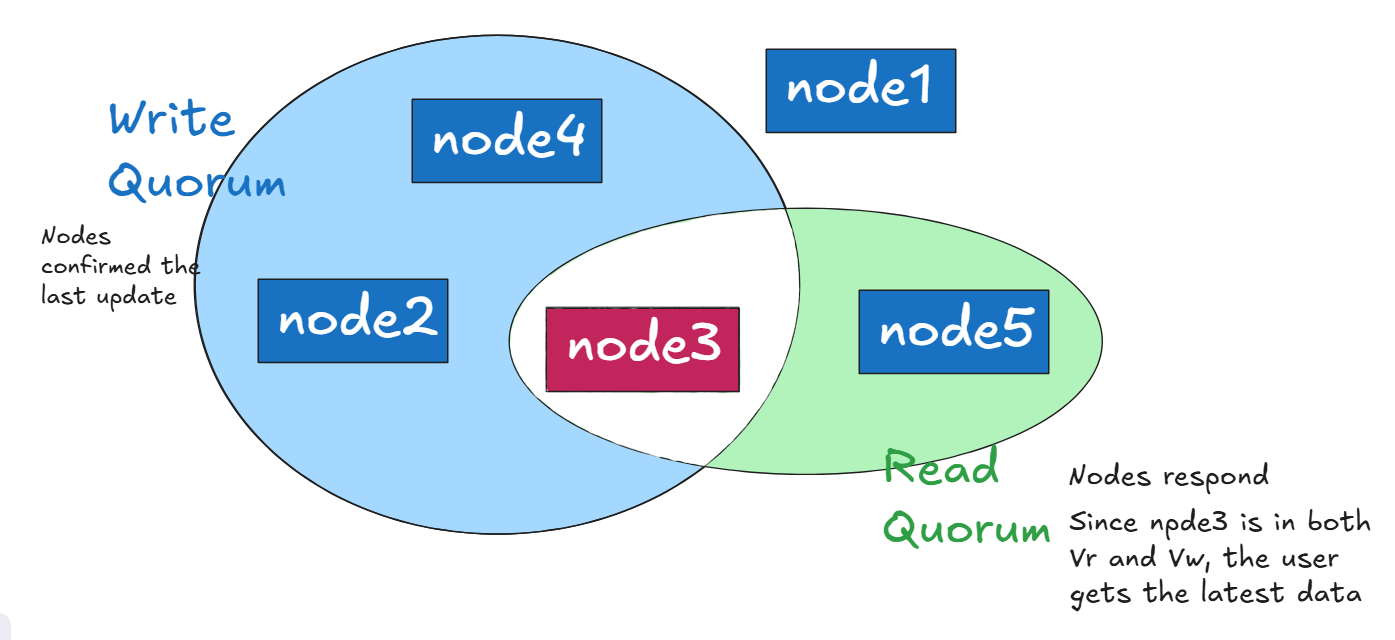
Quorums help balance the Consistency-Availability trade-off by ensuring that reads and writes involve a minimum number of nodes.
How Quorums Work:
- Vr + Vw ≥ V → Ensures that at least one node in the read quorum overlaps with a node in the write quorum, preventing stale reads or lost updates.
- Vw > V/2 → Ensures that at least one node always has the latest write, avoiding split-brain and conflicts.
Example - Imagine a distributed database with 5 replicas that store the same data. To prevent inconsistencies, the system requires a majority (N/2 + 1) of replicas to approve any change before it is confirmed.
| Quorum Setup | Read Quorum (Vr) | Write Quorum (Vw) | Conditions | Behavior |
|---|---|---|---|---|
| Strong Consistency | 3 | 3 | 3+3≥5 3>5/2 | Ensures latest data is always read but may slow writes. |
| Balanced Approach | 2 | 3 | 5≥5 3>5/2 | Optimizes both consistency and availability. |
| High Availability | 1 | 5 | 6≥5 5>5/2 | Very fast reads, but risk of stale data. |