Introduction to Distributed Systems
A distributed system is a system whose components are located on different networked computers, which communicate and coordinate their actions by passing messages to one another.
Why Do We Need Distributed Systems?
- Performance - Distributes computational load across multiple machines, leading to faster processing.
- Scalability - Allows systems to scale horizontally by adding more machines rather than upgrading a single machine.
- Availability - Ensures high availability and fault tolerance by distributing workloads and replicating data.
Fallacies of Distributed Computing
| Fallacy | Explanation |
|---|---|
| Global Clock Fallacy | No single global clock synchronizing all systems, leading to inconsistencies. |
| Network is Reliable | Networks experience delays, packet loss, and failures. |
| Latency is Zero | Communication delays exist and must be accounted for. |
| Bandwidth is Infinite | Limited bandwidth can lead to congestion. |
| Network is Secure | Networks are vulnerable to attacks and failures. |
| Topology Doesn’t Change | Nodes may join or leave dynamically. |
| One Administrator | Large-scale systems have multiple admins with different policies. |
| Transport Cost is Zero | Communication has overhead costs (latency, processing). |
Challenges in Designing Distributed Systems
Lots of challenges arise due to absence of global state and unreliable communication.
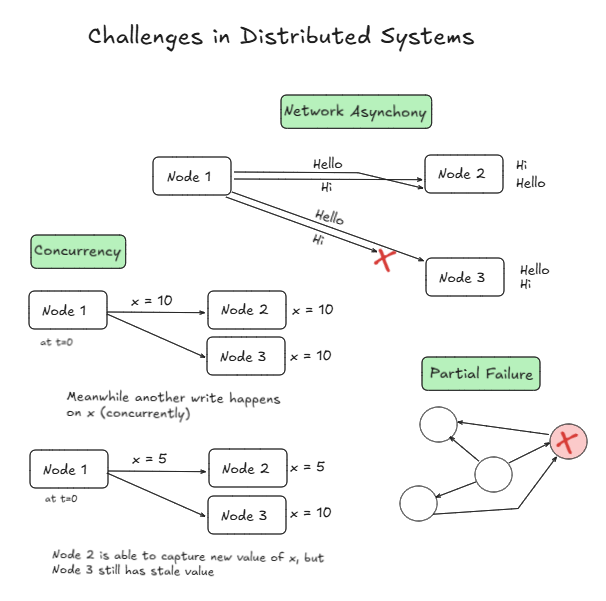
- Network Asynchrony - No guarantee that messages will be delivered in order or within a fixed time.
- Partial Failure - Some nodes can go down, thus maintaining atomicity can be a issue.
- Concurrency - Multiple computations may execute on the same data, requiring synchronization mechanisms.
Fundamental trade-offs in Distributed Systems
- Consistency Vs Availability (CAP Theorem) : A system can be consistent ( every node has consistent data at all times ) or available ( system remains operational even if a node fails ) Ex - In banking systems consistency is prioritizes while in social media availability.
- Cost Vs Performance : High performance distributed system often require more resources. Ex - Different pricing in AWS DynamoDB offers different performance.
Note - Safety property (something that must never happen) outweighs Liveliness property (something that should happen eventually ) in a distributed environment.
Types of Distributed Systems
Can be classified based on how they handle time and message delays.
- Synchronous : Each node has accurate clock and an upper bound on message transmission delay. Ex - Air Traffic control
- Asynchronous : No upper bound on how long it takes for a node to deliver a message. Ex - Internet
Types of Failures in Distributed Systems
Failures in distributed systems are inevitable, and systems must be designed to handle them gracefully.
| Failure Type | Description | How to Handle |
|---|---|---|
| Fail-Stop | Node stops permanently, and others detect it via communication. | Heartbeats and failure detectors |
| Crash | Node halts silently, and others assume failure based on timeout. | Heartbeats and failure detectors |
| Omission | Node fails to respond to incoming requests | Implement retries and acknowledgments. |
| Byzantine | Node exhibits arbitrary behavior, including sending incorrect or malicious messages. | Byzantine Fault Tolerance (BFT) algorithms like PBFT. |
Multiple Deliveries of a Message
Assume a Banking application where user is charged, but due to failed response, charges him again.

To deal with situations like these, we can use couple of strategies:
-
Idempotent Operation Approach : We apply an operation multiple times without changing the result. (change happens only on 1st call )
Ex - Adding a value to the Hashset.
-
De-Duplication Approach : Give a unique identifier to each message, so even if it delivered multiple times the recipient knows to discard the duplicates
Note - It is possible to have exactly-once processing in a distributed system, but not exactly-once delivery.